My Clanker Setup

A mate messaged me this week asking whether I'd ever written up my clanker setup — which harness I run, which models, what hardware, and whether I'd gone full Hermes or full OpenClaw. I started typing a reply, watched it turn into an essay, and decided it belonged here instead.
This is that post. In the first draft I called it a point-in-time snapshot and predicted that this space moves fast enough for some of it to be wrong in six months. It took two days: between draft and publish, the harness changed names underneath it — PAI became LifeOS — and the details below have been updated to match. The principles underneath are the part that holds — weight them accordingly.
The frame
The real move isn't using AI to do the thing — it's using AI to build tools that do the thing deterministically. I've written about that before, and it's the load-bearing idea in everything below. The model is the engine, not the product. The harness — the scaffolding of code, memory, permissions, and verification wrapped around the model — is where the leverage lives, and it's also where the safety lives.
Once you internalize that, "which model?" becomes the least interesting question on the list. The interesting questions are the ones my mate actually asked: what's the harness, where does the compute live, what's allowed to leave the house, and how do you know any of it works?
The harness
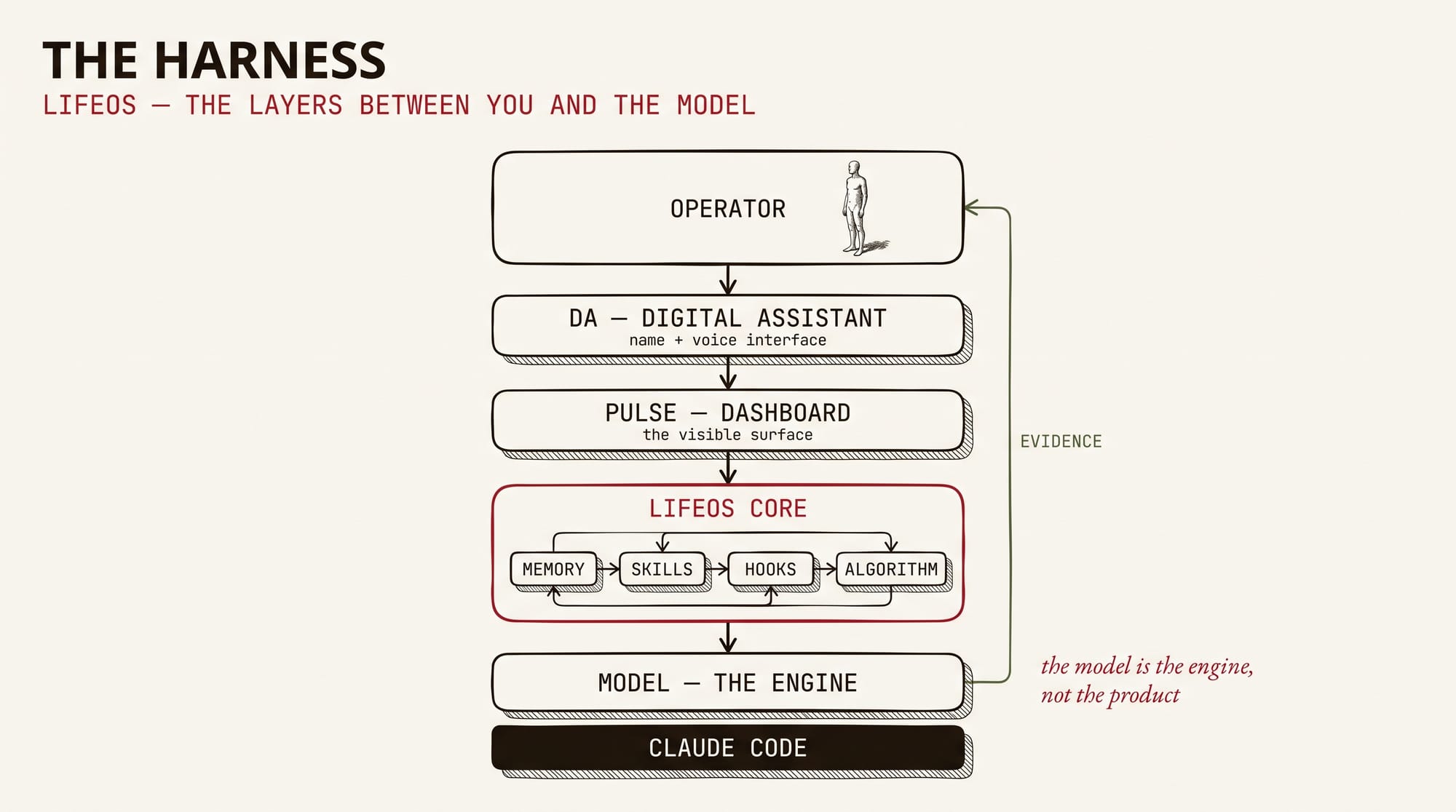
The spine is LifeOS — Daniel Miessler's open-source project, until recently called PAI, Personal AI Infrastructure — sitting on top of Claude Code. If you're starting from zero, start there. Out of the box it gives you the operating system around the model: skills (domain playbooks the agent loads on demand), hooks (deterministic code that fires before and after every action), a task algorithm that forces the system to define "done" as testable criteria before it starts working, and memory that compounds across sessions instead of evaporating when the context window closes.
The rename is the right call, because the frame outgrew the name. "Personal AI infrastructure" describes plumbing for getting work done, and for the first while that's what mine was. What it runs as now is closer to an operating system for a life: it holds my goals and tracks my current state against them, it knows the projects and people in my orbit, and every task it executes is a step in closing the gap between where things are and where I've decided they should be. The layering matters — the OS underneath (memory, skills, hooks, the algorithm), a dashboard that shows the whole thing running, and a digital assistant with a name and a voice as the interface on top. Anyone running one of these ends up naming their own, which is exactly the point of that layer.
Mine is heavily customized at this point — a long tail of accumulated skills, security hooks, and hard-won operational rules — but the bones are still recognizably the public project's bones.
The security posture is the part I'd call non-negotiable. The main loop runs a frontier Claude model with anti-prompt-injection scaffolding around it: external content is treated as data, never as instructions; commands get inspected before they execute; egress gets watched. None of that is vibes — it's enforced in code, in the hook layer, which is exactly why the harness matters more than the model. Models can be argued into things. Hooks can't.
The harness also buys me parallelism, which is my actual problem: parallel opportunities, and no patience for sitting around waiting on one agent to finish before the next thing starts. Skills plus background agents mean several workstreams move at once while I steer.
Models
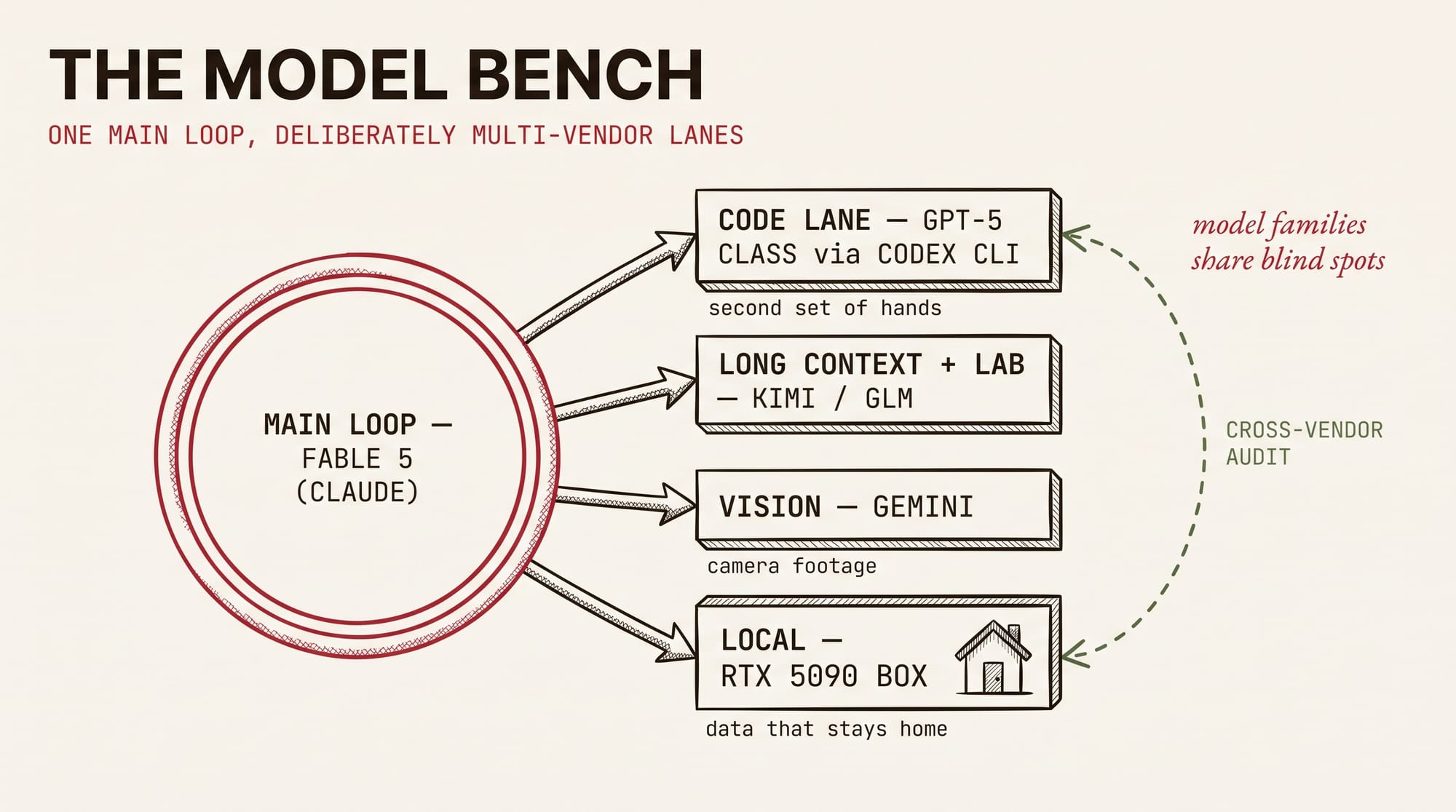
Claude for the main loop — Fable 5 since it landed, the top of the new Claude 5 family, with cheaper family members picking up classification, routing, and the other commodity calls where frontier capability is wasted. Around that, specialist lanes that are deliberately multi-vendor: a GPT-5-class code producer driven through the Codex CLI when I want a second set of hands on an implementation, Kimi and GLM for long-context and lab work, Gemini for vision-heavy pipeline jobs like classifying camera footage.
The multi-vendor part isn't accidental. Model families share blind spots the way development teams share blind spots, so my verification step includes a cross-vendor audit: one vendor's model reviewing work another vendor's model produced. It catches a class of error that same-family review reliably misses.
Local models run on an RTX 5090 box when the data shouldn't leave the network — more on that in a second.
Hardware
Nothing exotic: a Mac as the cockpit, an always-on Mac mini as the runner for scheduled jobs, automations, and message bridges, a hypervisor box for lab VMs, NAS for storage, and the aforementioned 5090 box for local inference. The mini is the unsung hero — the boring, reliable, always-on layer is what turns a chatbot into infrastructure.
The high side and the low side
This is the part I suspect most people rethinking their setup actually care about, and it's the part I'm still actively working on, so hold it loosely.
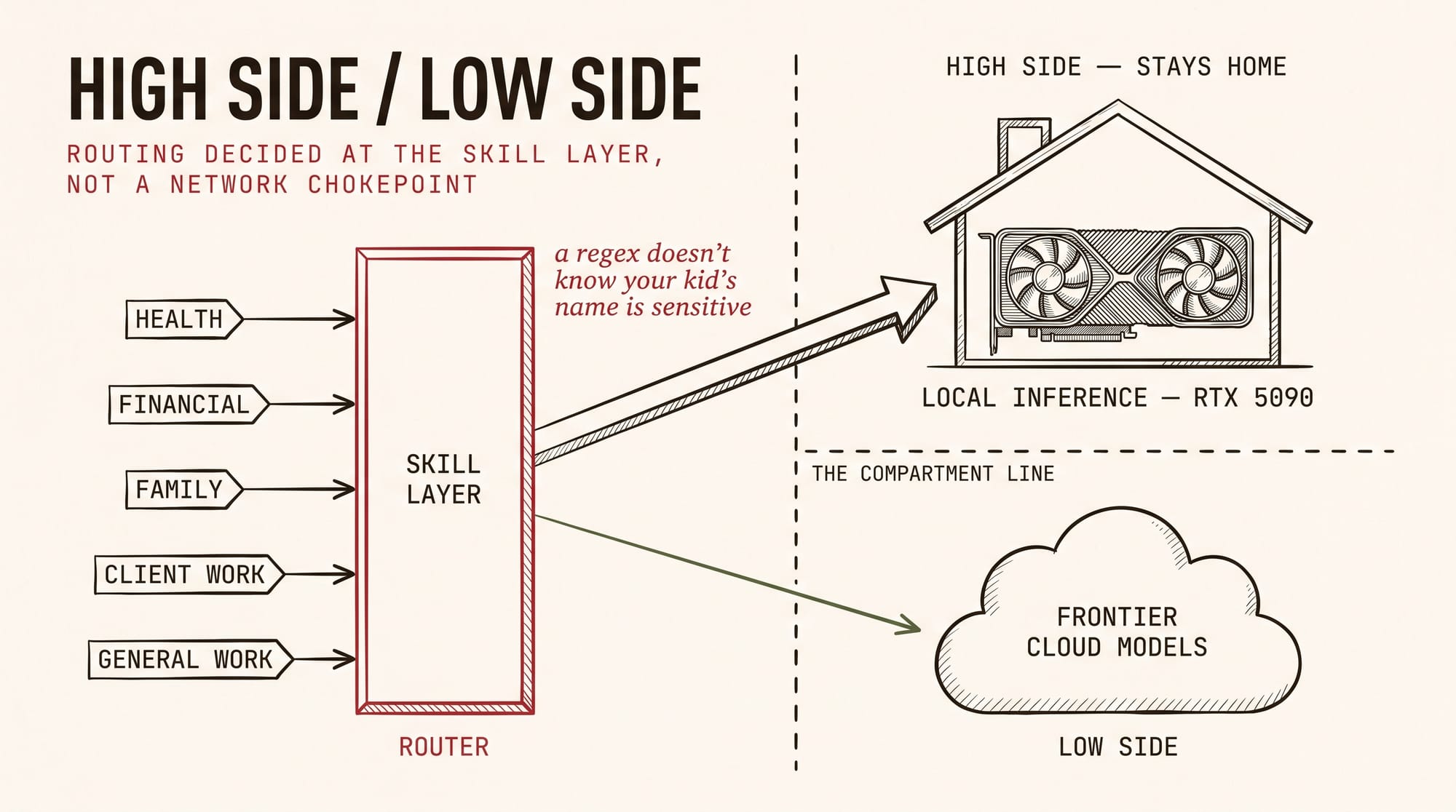
Not everything should leave the house. The way I think about it borrows from classified-network design: a high side and a low side. Sensitive classes of data — health, financial, family, client work — route to local inference on the 5090 box. General work rides the frontier cloud models, because capability still matters and the frontier is still the frontier.
The design decision that matters: the routing lives at the skill layer, not at a network chokepoint. The tool that touches the data knows what class of data it's touching, so the model choice happens per-task rather than per-conversation. Some folks solve this with a scrubbing proxy in front of the cloud models — strip or swap anything sensitive-looking before it egresses. That's a legitimate pattern, and probably the faster one to stand up. My bias is to make the routing decision where the context lives, because a regex doesn't know that your kid's name is sensitive and your CVE analysis isn't.
Honest admission: the plumbing is the easy part. Compartmentalization planning is the genuinely tricky bit — deciding what belongs on which side, what happens when a task spans both, and how much friction you're willing to eat for the separation. No framework does that design work for you.
The personal side
A work rig is where this starts; it isn't where it ends up. The same harness runs a growing share of the non-work life, and that's where the "operating system" framing stops being a metaphor. A sampling from the last few months: a camera pointed at the house finch nest in our yard, with the pipeline classifying footage, writing the daily entry, and publishing a little blog about the brood without me in the loop; health data pulled off the watch into the same memory the assistant reads; the tax and bookkeeping paper-chase, reconciled and chased down to the receipt; email triage across too many accounts, and bridges that pull the various message silos into one place; trip logistics, birthday planning, the family calendar; and a growth plan for a mate's gemstone business, built and maintained on the side.
None of those is impressive on its own — each is a small tool doing a boring thing reliably. The compounding is the point. The same memory, the same skills, the same verification culture apply whether the task is a client deliverable or making sure a school thing doesn't get missed, and every one of them makes the next one cheaper to build.
Hermes or OpenClaw?
Neither, fully. LifeOS stays the spine.
What I'm actively looking at is Hermes for the family and low-side lane — the household agent, distinct from the work system. Two things I like about it. It starts naive and learns quickly and iteratively: it builds its own scaffolding as it goes, skills grown from experience rather than shipped in the box. It's also been noticeably more performant than OpenClaw in my experience.
OpenClaw takes the opposite approach — it throws the kitchen sink at you on day one. Impressive capability surface; the problem is that in security terms the capability surface is the attack surface, and OpenClaw's is enormous, pre-enabled, and fed by a third-party skill ecosystem that has already shipped at least one confirmed-malicious skill. For a work rig operated by someone who reads every hook before it lands, that might be manageable. For a family-facing agent, "starts small and earns capability" is the right default posture — and right now that's Hermes.
How I know any of it works
The same way I'd know about any other system: assume it's lying until it proves otherwise.
The harness enforces this. Nothing gets to claim "done" without evidence — a screenshot, a live probe, a re-run, a diff. "Should work" is a banned phrase. That single cultural rule, enforced in the algorithm layer rather than in my willpower, catches more silent failures than anything else in the stack.
On top of that, adversarial testing: I feed the system hostile content on purpose, run it through prompt-injection gauntlets, and occasionally point it at CTFs built specifically to trip agents up. If your agent has never been attacked by you, it's been tested by nobody — and it won't stay nobody for long.
The cross-vendor audit is the last line: fresh eyes, different blind spots, no shared assumptions.
If you're rethinking yours
Three suggestions, in order:
- Pick the harness before the model. Models are interchangeable engines; the scaffolding is the product. Deterministic beats clever.
- Decide the compartments before the plumbing. High side, low side, and what's allowed to cross between them — the design work is the hard part, so do it first.
- Make verification a reflex. The agent that has to prove it did the thing is worth ten that say they did.
Build the tooling. Don't be the tooling.

Comments ·
members only